
2023年03月19日 13:48:12 来源:上海派拉软件股份有限公司 >> 进入该公司展台 阅读量:29
什么是Elasticsearch?
Elasticsearch(后简称ES)是一个基于Apache Lucene(TM)的开源搜索引擎。
为什么使用ES?
ES是Lucene面向企业搜索应用的扩展,极大的缩短研发周期。
注:本文主要围绕ES的优化,基础知识请移步~
在某省的大数据日志分析平台项目中,我们对网络设备日志,操作系统日志,数据库日志,中间件日志,业务日志进行7*24小时采集,搜索(能够搜索2个月以内的数据)由于日志量十分的庞大(日志源大约在1000个左右),并且当业务繁忙的时候(工作日9:00-17:00)中间件日志和业务日志的产生会出现井喷式的爆发,每天大约1.2T的数据量,但由于系统组各方面原因,现有硬件资源无法支撑如此高的并发。为此,团队对ES(底层存储)进行深度优化,使其能够应对场景。
描述:
数据产生的量平均大约为: 15MB/秒≈15000条/秒
业务繁忙期大约为: 20MB/秒≈20000条/秒
机器配置为:
CPU:80个核心(超线程)
内存:256G
磁盘:7块机械硬盘(每块14T)
机器数量:1台
机器所安装的组件,以及数据流走向
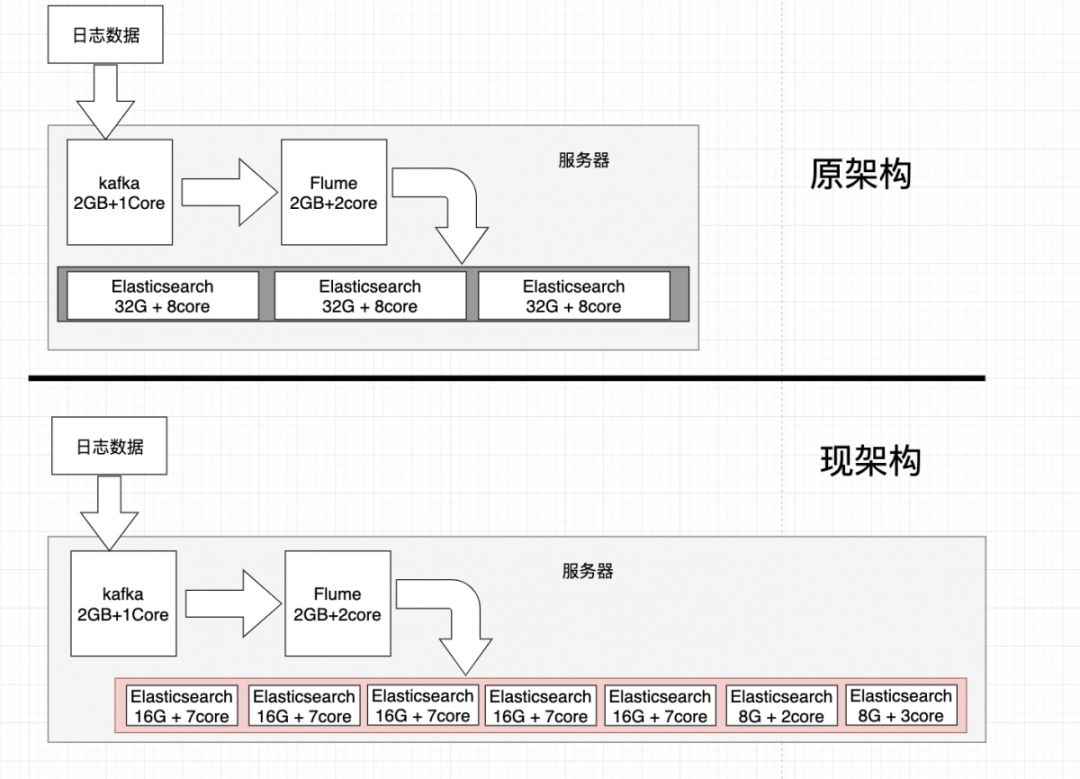
服务器上安装了:
Kafka(2GB + 1core) * 1
Flume(2GB + 2core) * 1
ES(32G + 12core) * 3

遇到的问题
数据在kafka中严重堆积(数据输入速度大于落地速度),ES在运行一段时间后写入速度只有1M/秒。导致最后直接瘫痪奔溃。
优化后
1. 数据实时落地ES并且在Kafka无堆积
2. 每天1.2T数据增量,稳定无崩溃
3. 2个月的数据大约有70TB≈700亿条
4. 普通搜索匹配在10秒内返回结果(使用缓存)
5. ES占用内存大约为96G
6. ES占用CPU 大约为40个核心
优化后ES的节点信息
在每一块硬盘上部署了1个ES节点,共计部署了7个节点
前5个节点 每个节点16G内存,作为data节点(详见下面配置)
后2个节点 每个节点8G内存,一个作为master,一个作为client(详见下面配置)
优化详情
这里提出来的只是一种优化点,并不是说一定要按照这个配置,毕竟具体场景要具体分析。
硬件优化
a) 硬盘使用SSD,并且调整I/O调度算法为RAID0,其实硬盘可以说是ES的一个瓶颈了,但是由于项目经费问题,所以优化的时候并没有考虑上SDD...当然土豪请随意...
b) 每个节点ES CPU至少大于8Core
c) 每个节点ES分配内存至少大于8G
d) 不要使用NAS
配置优化
a) 调整ES所用的内存大小,建议不超过32G,内存最小设置成一样
为什么不超过32G?
其基本原因是JVM使用所谓的HEAP内存来存储对象指针。为了提高效率,Java使用了所谓的压缩普通对象指针(OOP)。超过32 GB的HEAP,Java需要使用常规的64位指针。这实际上大大减少了HEAP中可以存储的对象数量,大约50 GB的HEAP与大约30 GB的大约相同。
***此配置在jvm.options设置
###在此场景中我们的data节点内存每台为16G,master和client节点各为8G
b) 合理配置每个节点的角色data/master/client
node.master:true 这个属性表示节点是否具有成为主节点的资格,主节点负责存储元数据和任务调度,以及维护整个集群状态
node.data:true 这个属性表示节点是否存储数据,
如果2个属性都为false,则视为client节点,该节点只负责用户请求,实现请求转发,负载均衡等功能
***此配置在elasticsearch.yml设置
###在此场景中我们的5台data节点配置为:
node.master:false
node.data:true
1台master节点配置为:
node.master:true
node.data:false
1台client节点配置为:
node.master:false
node.data:false
c) 调高index的缓存indices.memory.index_buffer_size
***此配置在elasticsearch.yml设置
###在此场景中我们的配置为indices.memory.index_buffer_size:30%
d) 调高线程数
thread_pool.search.queue_size(搜索队列线程数)
thread_pool.index.queue_size(索引队列线程数)
***此配置在elasticsearch.yml设置
###在此场景中我们的配置为
thread_pool.search.queue_size:1000
thread_pool.index.queue_size:200
e) 调整索引时候的配置
1) settings.number_of_replicas 副本数 默认为1
建议写入时数据量很大的情况下,将副本数设置成0,等压力小后,将其再设置成1,因为副本数将直接影响你的磁盘开销.
2) settings.number_of_shards 分片数量 默认为5
参考公式: 分片数量=总节点数/(分片副本数量+1)
3) settings.index.translog.sync_interval translog同步到磁盘的时间间隔
什么是translog?
lucene索引过程中,数据会首先据缓存在内存中直到达到一个量(文档数或是占用空间大小)才会写入到磁盘。这就会带来一个风险,如果在写入磁盘前系统崩溃,那么这些缓存数据就会丢失。es通过translog解决了这个问题,每次写操作都会写入一个临时文件translog中,这样如果系统需要恢复数据可以从translog中读取。
4) settings.index.translog.durability tanslog同步到本地的方式
5) settings.index.translog.flush_threshold_size 满足translog同步的容量 默认为512m
6) settings.index.refresh_interval 索引的刷新时间间隔 默认为:1s,调大间隔可以很明显感觉到es的效率高了不少
7) settings.index.merge.scheduler.max_thread_count 调高合并的线程
默认为:Math.max(1, Math.min(3, Runtime.getRuntime().availableProcessors() / 2))
8) settings.index.merge.policy.max_merged_segment 分段大小 默认为5gb
在正常的合并过程中产生的分段的大小。此设置是近似值:合并后的段大小的预估值是由被合并分段的大小计算出来的(删除文档补偿百分比)
9) settings.index.merge.policy.segments_per_tier 每层所允许的分段数 默认为10
较小的值意味着更多
的合并,但是存在较少的分段。默认:10。请注意,这个值必须 >=max_merge_at_once 不然就会强制执行太多的合并。
***此配置是在ES启动后以api的方式发送给ES
###在此场景中我们的配置为
"number_of_shards": 7,
"index.translog.sync_interval": "120s",
"index.translog.durability": "async",
"index.translog.flush_threshold_size": "5g",
"number_of_replicas": "0",
"index.refresh_interval": "60s",
"index.merge.scheduler.max_thread_count": 20,
"index.merge.policy.max_merged_segment": "2gb",
"index.merge.policy.segments_per_tier": "24"
设计优化
a) 路由
当我们查询文档的时候,Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?它其实是通过下面这个公式来计算出来
shard = hash(routing) % number_of_primary_shards
routing 默认值是文档的 id,也可以采用自定义值,比如用户 id。
不带 routing 查询
在查询的时候因为不知道要查询的数据具体在哪个分片上,所以整个过程分为 2 个步骤
分发:请求到达协调节点后,协调节点将查询请求分发到每个分片上。
聚合: 协调节点搜集到每个分片上查询结果,在将查询的结果进行排序,之后给用户返回结果。
带 routing 查询
查询的时候,可以直接根据 routing 信息定位到某个分配查询,不需要查询所有的分配,经过协调节点排序。
向上面自定义的用户查询,如果 routing 设置为 userid 的话,就可以直接查询出数据来,效率提升很多。
b) Filter VS Query
尽可能使用filter
Elasticsearch 针对 Filter 查询只需要回答「是」或者「否」,不需要像 Query 查询一下计算相关性分数,同时 Filter 结果可以缓存。
c) 对index做分区
一个index能存放的数据是有限的,就像数据库一样,在数据量很大的情况下,我们一般会将其进行分表(分区),比如用户的访问日志,我们的index可能以时间做区分比如 index-%{yyyy-MM-dd} 这样每天生成一个index,保证index不会因为数据太多而”爆炸”
d) 深度分页
在使用分页的时候尽量使用scroll来分页,From+Size会让你的CPU占用率像直升机一样飙高,然后坠机(程序奔溃)…
总结
优化前后对比
| | CPU占用 | 内存占用 | ES节点数 | 每秒可接受数据量(稳定不宕机) | 数据实时性 |
| 优化前 | 36core | 96G | 3 | 5MB/S | 2秒以内 |
| 优化后 | 40core | 96G | 7 | 20MB/S | 60秒以内 |
架构对比
优化思路
1. 调整ES的索引刷新间隔
2. 调整ES的translog刷新策略
3. 调整索引合并策略
4. 调整shards数量
5. 调整副本数量
6. 调整缓存策略
7. 调整搜索,合并,刷新的线程数
8. 设置合理的es节点角色
9. Index合理分区
10. 尽量使用filter
11. 尽可能使用路由策略
12. 使用SSD



